
Optimizing the Stack: Why Databricks and Palantir Are Better Together
A joint perspective from Meridian Partners and Blueprint Technologies
Most enterprises running Palantir are overpaying for capabilities the platform was never designed to deliver. That’s not a knock on Palantir, it’s a statement about how deployments actually evolve. What starts as an operational application layer gradually absorbs data engineering, pipeline orchestration, storage, and compute workloads it shouldn’t own. The result is inflated cloud spend, architectural complexity, and a platform doing four jobs when it should be doing one extremely well.
Databricks exists to solve exactly the problems Palantir shouldn’t be solving. It is purpose-built for large-scale data engineering, cost-efficient compute, and advanced analytics. Moving pipelines, storage, and compute to Databricks while preserving Palantir’s Ontology, semantic layer, and operational workflows is the architectural correction most Palantir customers need and the one that unlocks the most value from both platforms.
This isn’t a theoretical integration. In March 2025, Databricks and Palantir announced a formal strategic product partnership. Over 150 joint customers (including the U.S. Department of Defense, Department of the Treasury, BP, United Airlines, and R1) are already running production workloads on the combined architecture. The partnership combines Palantir’s Artificial Intelligence Platform (AIP) and Ontology with Databricks’ Data Intelligence Platform to deliver real-time, AI-powered autonomous workflows at reduced total cost of ownership.
Who we are: Meridian Partners + Blueprint Technologies
Meridian Partners is a fast-growing technology strategy and advisory firm with leadership drawn from Palantir, Microsoft, Amazon, and DoorDash. Meridian operates as embedded operators, not career consultants, bringing executive-level technology strategy, data architecture, and platform expertise directly into client organizations. Meridian’s deep partnerships within the Databricks and Palantir ecosystems position the firm to advise on platform strategy, integration architecture, and the cost optimization work that drives measurable ROI.
Blueprint Technologies is a multi-award winning Databricks partner that brings extensive hands-on experience designing and operating mission-critical Databricks Lakehouse environments for companies and agencies at all levels of size and complexity. Over the past four and a half years, Blueprint built and sustained a suite of five Palantir-based applications for the U.S. Army, including workflow routing tools for Functional Support Agreements, contract trackers, and operational dashboards. Blueprint operates as a long-term product delivery partner with deep expertise in solution architecture, agile development, and commercial innovation in highly regulated environments.
Together, Meridian and Blueprint cover the full lifecycle. Meridian leads on strategy, use-case and workflow design and implementation, and Palantir platform optimization, including the migration of pipelines, compute, and storage workloads that unlock cost savings. Blueprint delivers Databricks application development, architectural design, agentic configuration, and ongoing operational support. This partnership gives clients a single team that understands both sides of the stack and can execute the migration, integration, and optimization work end to end.
What Palantir does really well…and where it needs help
Palantir’s strength is the operational layer. Foundry’s Ontology provides a semantic model that maps raw data to real-world business objects such as assets, customers, orders, workflows and gives non-technical users a way to interact with complex data safely. The Ontology is what separates Palantir from every other data tool on the market: it becomes the shared language for building applications, linking AI outputs to decisions, and enforcing governance by design. Every dashboard, workflow, AI agent, and application reads from and writes to the same Ontology rather than scattered silos.
On top of the Ontology, Palantir’s AIP connects LLMs directly to business objects, enabling agentic workflows that trigger real actions in the form of work orders, compliance flags, approval routing with human-in-the-loop controls and full audit trails built in by design. The platform excels at workflow routing, form-based data entry, operational dashboards, and turning analytical outputs into daily business actions.
Where Palantir needs Databricks, or more precisely, where it becomes expensive and inefficient, is in the data engineering layer. Running heavy ETL pipelines, storing large volumes of raw and transformed data, and executing compute-intensive workloads on Palantir infrastructure costs significantly more than equivalent work on Databricks. Palantir’s pipeline tooling works, but it wasn’t designed to compete on cost-per-query or cost-per-terabyte with a platform built specifically for those economics. Organizations that use Palantir for storage, compute, transformation, and operations are paying a significant premium for workloads that belong somewhere else.
What Databricks brings to the equation
Databricks is purpose-built for exactly the workloads Palantir customers should be offloading: data ingestion, transformation, storage, compute, and advanced analytics. The Lakehouse architecture provides a single platform for structured and unstructured data, with Delta Lake handling ACID transactions, schema enforcement, and time travel at scale. Unity Catalog delivers centralized governance, fine-grained access controls, data lineage, and audit logging across the entire data estate.
From a cost perspective, Databricks offers significant advantages over running equivalent workloads on Palantir infrastructure. Serverless compute scales to zero when idle and features like its Photon engine help accelerate SQL workloads at lower cost. Spot instance integration and auto-scaling reduce compute spend further. Organizations routinely see 30–60% cost reductions when migrating pipeline and storage workloads from Palantir to Databricks, depending on volume and complexity.
Databricks also provides the foundation for machine learning and advanced analytics. MLflow handles experiment tracking, model registry, and deployment. Feature engineering runs at scale. And critically for the Palantir integration: models trained and registered in Databricks can be registered directly within Palantir Foundry’s Ontology, making them immediately deployable in operational applications. This closes the gap between experimental data science and real-world operational deployment.
The right architecture: clear separation of concerns
The integration thesis is straightforward: move data pipelines, storage, and compute to Databricks. Keep the Ontology, semantic modeling, and operational applications on Palantir. Connect them through purpose-built integration that minimizes data movement and maximizes each platform’s strengths.
The formal partnership between Databricks and Palantir has produced a technically mature integration with three critical capabilities that make this separation work in production.
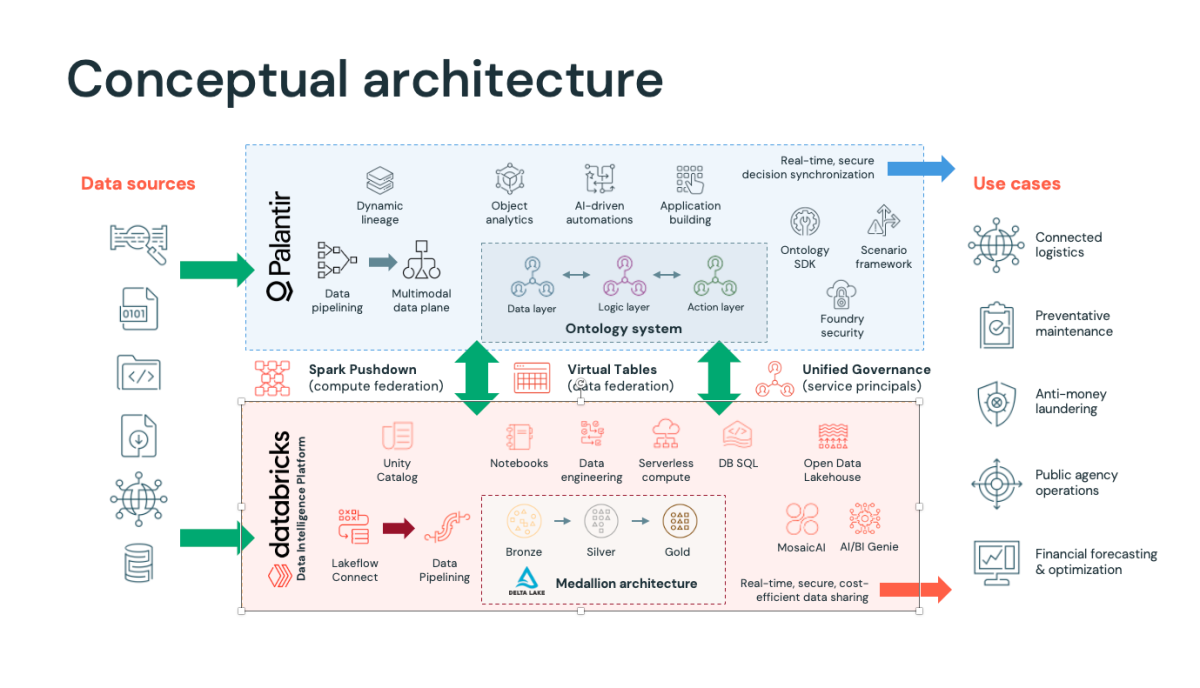
Zero-copy data access via Virtual Tables
Palantir’s Multimodal Data Plane (MMDP) enables Foundry to register Databricks Unity Catalog tables as Virtual Tables directly accessible within Foundry without copying data into Palantir’s storage layer. Data stays in Databricks. Palantir reads it in place. This eliminates the redundant storage costs, synchronization complexity, and stale-data risk that plagued earlier integration approaches. Authentication leverages service principals and workload identity federation, removing hard-coded credentials from the architecture entirely.
Spark Pushdown for compute federation
When a user defines a transformation or pipeline within Palantir Foundry’s tools like Pipeline Builder, Code Repositories, or Code Workspaces, the execution is automatically pushed down to Databricks’ serverless compute infrastructure via Spark Pushdown. The compute runs where the data lives. Customers get to use the tools they’re familiar with in Foundry while benefiting from Databricks’ performance, scalability, and cost economics for data processing. Data is read from Databricks, processed using Databricks compute at Databricks storage, and the output is written directly back to Unity Catalog; all without moving data between platforms.
Bi-directional data and model flow
The integration is genuinely bi-directional. Databricks-managed, or external tables flow into Palantir’s Ontology system spanning the data layer, logic layer, and action layer for operational applications. Operational data generated in Palantir such as approvals, workflow outputs, user inputs, action logs can be written back to Databricks for downstream analytics. ML models trained in Databricks can be registered in Foundry’s Ontology and immediately deployed within AIP-powered workflows and agents. Both platforms act as equal participants rather than falling into a one-way upstream/downstream dependency.
What each platform owns
Databricks (Data Intelligence Platform): Lakeflow Connect and data pipelining for ingestion, Medallion architecture (Bronze → Silver → Gold) on Delta Lake for storage and transformation, serverless compute and DB SQL for processing, Unity Catalog for centralized governance, Notebooks for data engineering and science, and Mosaic AI and AI/BI Genie for machine learning and analytics.
Palantir (Foundry + AIP): Data pipelining and dynamic lineage via the Multimodal Data Plane, the Ontology system (data layer, logic layer, and action layer), object analytics, AI-driven automations, application building, Ontology SDK and Scenario Framework for extensibility, and Foundry Security for enterprise-grade access control.
The integration layer: Spark Pushdown for compute federation, Virtual Tables for data federation, and Unified Governance via service principals connecting Unity Catalog permissions to Foundry’s security model.
The key architectural principle: data lives in Databricks and is consumed by Palantir through Virtual Tables. Compute runs on Databricks infrastructure via Spark Pushdown. The Ontology, application logic, and operational workflows remain in Palantir where they deliver the most value. This eliminates the most common cost traps in Palantir-heavy deployments: redundant storage, over-provisioned compute for pipeline workloads, and duplicated governance overhead.
What this looks like in practice
The Palantir + Databricks combined architecture allows companies to drive high-value enterprise use cases across multiple industries:
Connected Logistics: A CPG manufacturer manages a global supply network with data flowing from ERP systems, logistics providers, and demand planning tools. Databricks consolidates and transforms that data through Medallion architecture, runs demand forecasting models, and maintains a governed data lake. Palantir’s Ontology maps those data assets to real-world supply chain objects like SKUs, facilities, shipments, suppliers and provides planners with applications to reroute shipments, adjust production schedules, and respond to disruptions. Operational actions taken in Palantir are written back to Databricks via the bi-directional integration for closed-loop analytics.
Preventive Maintenance: A midstream energy company runs predictive maintenance models across thousands of sensors on pipelines, compressor stations, and processing facilities. Databricks ingests IoT telemetry at scale, trains ML models for failure prediction via MLflow, and stores historical data in Delta Lake. Those models are registered in Palantir’s Ontology, where AIP-powered agents generate automated maintenance schedules, route work orders to field crews, and provide supervisors with real-time operational dashboards. Spark Pushdown means the heavy model training runs on Databricks serverless infrastructure at a fraction of what it would cost on Palantir.
Anti-Money Laundering: Financial institutions use Databricks to process massive transaction volumes, run pattern recognition models, and maintain regulatory data lakes. Palantir’s Ontology maps transactions, accounts, entities, and alerts into an integrated investigation workspace. AIP-driven automations flag suspicious patterns and route cases to compliance analysts through workflow applications with full audit trails that are critical for regulatory compliance.
Public Agency Operations: The partnership is already serving mission-critical outcomes for the U.S. Department of Defense, Department of the Treasury, and Department of Health and Human Services. In classified and high-security environments, the integration leverages Palantir’s military-grade multimodal security system alongside Unity Catalog’s governance controls, delivering AI-powered autonomous workflows within the strictest compliance frameworks.
Financial Forecasting and Optimization: Healthcare systems and enterprise finance organizations use Databricks for large-scale claims processing, revenue cycle analytics, and predictive modeling. Palantir’s Ontology maps financial objects such as patients, encounters, claims, providers and AIP agents help operational teams act on forecasts in real time, manage care coordination, and optimize resource allocation. Virtual Tables ensure the financial data stays in Databricks; Palantir reads it in place.
Start with an assessment
If you’re running Palantir today and your cloud spend keeps climbing, the answer probably isn’t more optimization within Palantir. It’s moving the right workloads to the right platform.
Meridian and Blueprint offer a Course of Action Assessment that evaluates your current Palantir deployment, identifies workloads that should migrate to Databricks, quantifies the cost savings, and delivers an architectural roadmap for integration. The assessment covers Virtual Table configuration, Spark Pushdown setup, Unity Catalog governance alignment, and Ontology design for the optimized architecture. It typically runs four to six weeks and produces a clear, actionable plan with measurable ROI targets.
Reach out to the Meridian or Blueprint team to get started.